
How biological inspiration and mathematical efficiency created the backbone of modern computer vision.
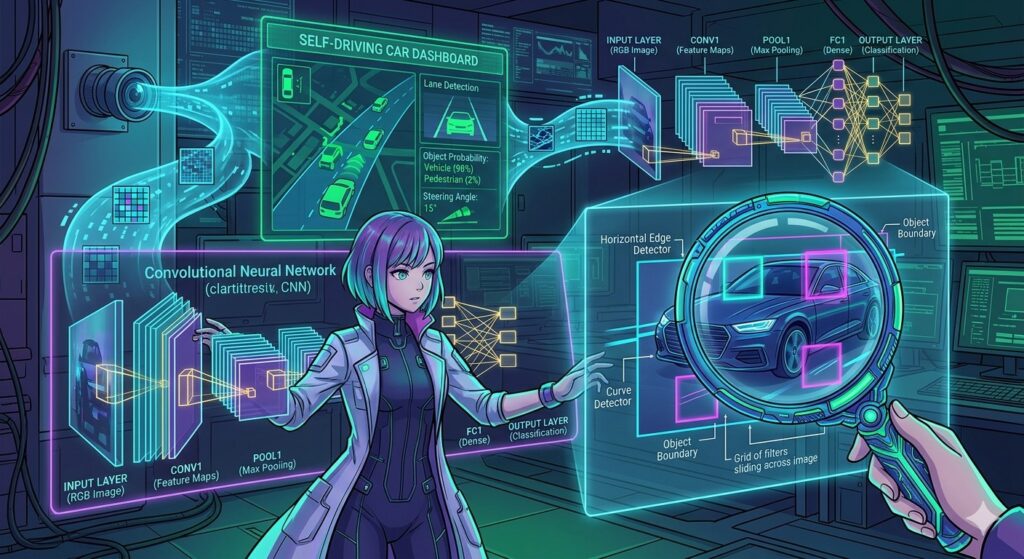
This week, I concluded my three-part journey into deep learning with Module 17: Convolutional Neural Networks (CNNs). If standard neural networks are the “brain,” then CNNs are the “eyes”. Originally designed for computer vision, these architectures are now revolutionizing everything from natural language processing to financial forecasting.
Here are the core takeaways from Module 17:
1. The Problem of Scale
Traditional fully connected networks struggle with high-resolution images because of “parameter explosion”. For example, a single 1000×1000 pixel color image has 3 million input features. A network with just one hidden layer could require 3 billion parameters, leading to massive overfitting and unfeasible memory requirements.
2. The Biological Blueprint
CNNs are directly inspired by the mammal visual cortex. Research by Hubel and Wiesel in the 1950s discovered that our brains don’t look at a whole image at once; instead, small regions of cells—local receptive fields—are sensitive to specific patterns like horizontal or vertical lines. CNNs mimic this by building complex patterns from simple building blocks.
3. How CNNs “See”: The Building Blocks
- Convolutional Layers: These use small, learnable filters (kernels) that slide across the input to detect specific patterns, such as edges or textures.
- Pooling Layers: These perform downsampling (like max pooling) to reduce the spatial size of the data, making the model more efficient and less sensitive to small shifts in an image.
- Flattening & Fully Connected Layers: At the end of the network, the extracted features are converted into a vector to make the final classification (e.g., “This is a cat”).
4. Efficiency through Weight-Sharing
The secret sauce of CNNs is weight-sharing. Instead of learning a new detector for every pixel, the same filter is applied across the whole image. This can reduce a model with 14 million parameters down to fewer than 500, making training faster and far more accurate.
5. Real-World Power: Self-Driving Cars
We explored a landmark case study by NVIDIA where a CNN performed “end-to-end” learning for self-driving vehicles. By training on raw footage from human drivers, the network learned to output steering commands directly from camera images. In real-life road tests, the vehicle achieved 98% autonomy, proving that these networks can handle the complexity of the physical world.
Conclusion
CNNs aren’t just mathematical tools; they are the “digital cousins” of our own visual systems. By combining hierarchical feature extraction with massive parameter efficiency, they have moved AI from a research curiosity to an industry cornerstone.