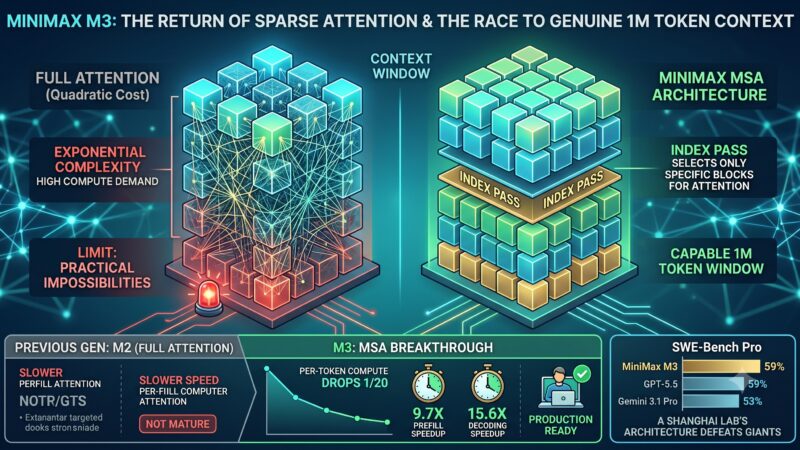
BreakthroughsNews MiniMax M3 and the Return of Sparse Attention: What Just Changed in the Long-Context Race A Shanghai lab just shipped a model that does at 1M tokens what full attention can’t do at any price. The architecture…
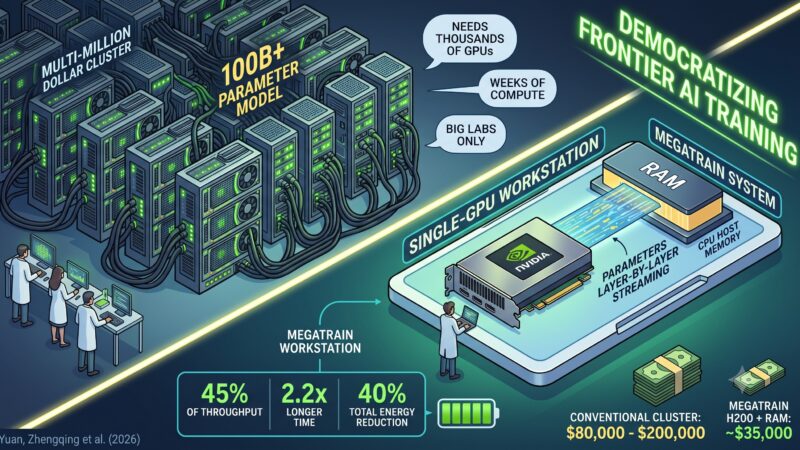
BreakthroughsNews One GPU to Train Them All: What MegaTrain Changes About Who Gets to Build AI Until now, training a 100B+ parameter model required a cluster, a multi-million dollar budget, and a very patient CFO. A new paper…