
Breaking down the 3 pillars of ML: Labeling stuff, finding patterns in chaos, and trial-and-error.
Machine learning (ML) is an approach to programming in which computers learn from
data to solve a task without receiving explicit instructions.
The three types of Machine Learning techniques
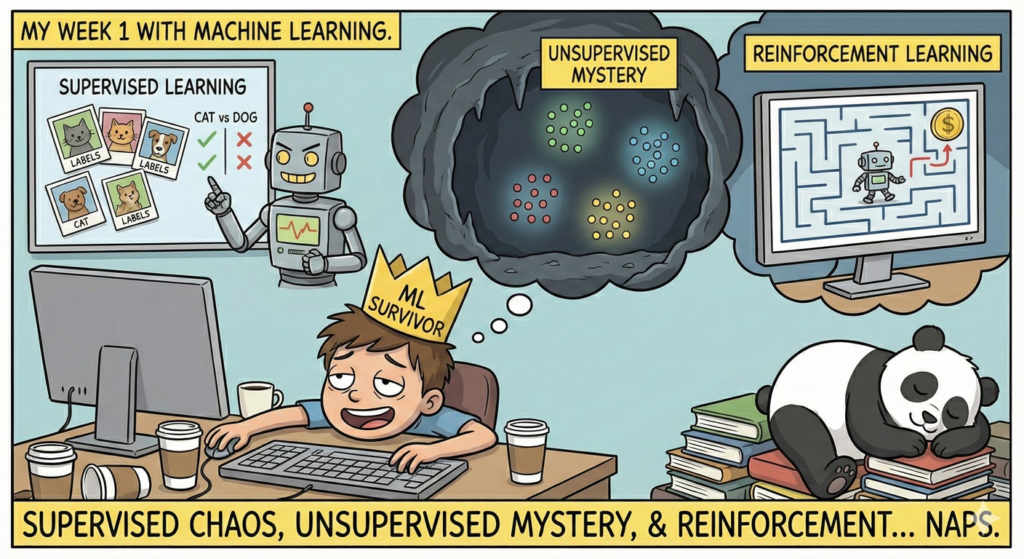
Supervised learning is a technique in which the model is trained on a labeled training set. For example, you will train a model to recognize dogs and cats on images. You will have to provide the model with a set of images on which it clearly states which image represents a dog and which image represents a dog.
This will be used in mainly two cases: Regression (predicting the price of an house based on some criteria like square meters, number of bedrooms, …) or Classification (identify dogs and cats on images).
As opposed to Supervised learning, Unsupervised learning is a technique in which the model is trained on an unlabeled training set.
This will be used in three main cases: Clusterization in which we group similar data points into clusters, Anomaly Detection in which we identify data points that deviate from standard patterns and Dimensionality Reduction in which we reduce the number of dimensions, from example from 3 axis (x, y. z) to only 2 axis (x, y).
Reinforcement learning is a technique in which the agent or model learns by making decisions and getting a reward if the decision is correct and a penalty if the decision is wrong.
Trainning Set
Training sets are use both for supervised or unsupervised learning. A training set will contain the features (set of data used to train the model) and for the supervised learning only, this will contain the target, which is the expected outcome.
Within the Features, data points can be of three different data types:
* Numerical
* Dates/Time (that would need to be converted to Numerical).
* Categorical which can either be Ordinal (it follows a natural order like grading from A to F) or Nominal(it does not follow any natural order like the gender).
Most ML models only work with numerical data points, so it is important to convert all data points into numerical data points.
Typical ML Workflow
- Get the data – It is not only about fetching the data, it is also about understanding KPIs and the results that we would consider as satisfactory. An example for that step could be: “A real estate agency records all sales made in the past 5 years across a region and convert that into a CSV file. The goal is to be able to predict house prices with an accuracy above 89%.“
- Data pre-processing – This is the step that will see us ensure that the training set is good to be used. This would mean data cleaning (missing data points, converting non-numerical values) and understanding the data set to see if this is possible to improve the data set. For example, it would mean making sure that we have all the house prices and all the house surfaces in the data set. The
scikit-learnlibrary (imported assklearn) will be used. - Modeling – This is a three step phase, with 1) the selection of the appropriate model, 2) with the tuning of the Hyperparameters and 3) with the evaluation of the model (based on unused data). The k-nearest neighbors algorythm (
KNeighborsClassifierfromsklearn) will be used. - Deployment – The model should be constantly monitored and updated with new data when available.
Data Pre-Processing
The sklearn library is heavily used for data pre-processing and its main objects are:
- Estimator – This is used to train a model by using the
.fit()method. However, an estimator does not return any outcome so this is of limited usage. - Transformer – The transformer (also an estimator) object first needs to learn from data by using the
.fit()method and then use the.transform()method. The method.fit_transform()does the two steps through a single method. - Predictor – The predictor (also an estimator as it has the
.fit()method) is an object used to make prediction by using the.predict()method. - Model – The model object (also a predictor) use the
.score()method to calculate a score to measure the predictor’s performance.
Data Cleaning
Identifying & Add/Delete Missing Data
In Pandas, missing data are represented by NaN.
To identify the number of missing values, you should use: DataFrame.isna().sum().
To display all rows that contains at least one missing value: DataFrame[DataFrame.isna().any(axis=1)].
To remove rows with missing values: DataFrame[DataFrame.isna().sum(axis=1) < 2]. Note that the number in bold is used to remove rows that have at least 2 missing values.
To impute (or replace) cells with missing values, we can use the SimpleImputer() method (from sklearn.impute import SimpleImputer). The following parameters can be used:
missing_value– placeholder for the missing value (default isnp.nan).strategy– the strategy used to replace missing values (default is ‘mean’).- ‘
mean‘ – Use the mean of each column. - ‘
median‘ – Use the median value of each column. - ‘
most_frequent‘ – Use the most frequent value for each column. - ‘
constant‘ – Use a fixed value specified in fill_value.
- ‘
fill_value– define the value to fill in whenstrategy='constant'.
Address Categorical Data
To encode ordinal data, use OrdinalEncoder(), it converts ordinal categories into integer starting from 0. The challenge lies in specifying the categories properly. To do this, we need to list all the unique categories by using DataFrame['column_name'].unique().
For example, we can have a column that identify the main_category of a product with 5 entries: Electronics, Food, Beverage, Beauty, DIY. Using the .unique() method will list all unique value, allowing you then to create a list of categories: main_cat_list = ['Electronics', 'Food', 'Beverage', 'Beauty', 'DIY'] and then create an OrdinalEncoder by using encoder_main_cat = OrdinalEncoder(categories=[main_cat_list]).
If you have more than one column to work on, you can pass several lists like ordinal_encoder = OrdinalEncoder(categories=[list1, list2, list3, ...]).