
Three papers, three institutions, one uncomfortable conclusion for the AI industry
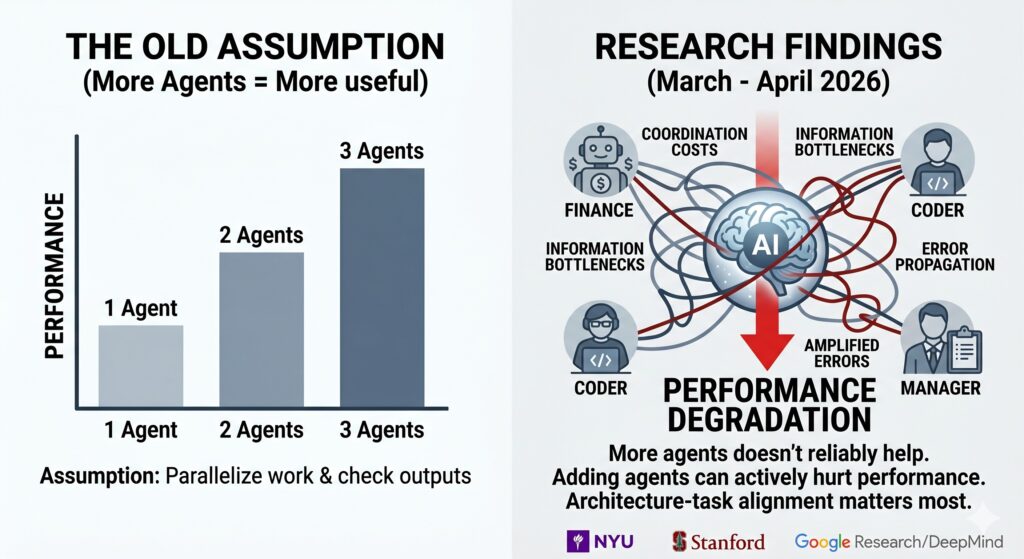
There is a prevailing assumption baked into how we talk about AI agents right now. It goes something like this: if one AI agent is useful, many AI agents working together must be more useful. Divide the problem, parallelize the work, check each other’s outputs. It sounds like common sense. It maps neatly onto how we think about human teams.
Three independent research groups decided to actually test this assumption. Their papers landed in March and April 2026, and while they come at the question from very different angles, they land in roughly the same place. The results are worth paying attention to, not because they say multi-agent systems are useless (they don’t), but because they tell you precisely when they’re useful, and when they’re not.
Let me walk you through what they found, where they agree, and what it means if you’re building or deploying AI systems today.
The Three Papers
Before getting into the findings, a quick map of what each group studied:
NYU (Kulkarni et al., March 2026) ran a large-scale production benchmark on financial document processing. They fed 10,000 SEC filings (10-K, 10-Q, 8-K reports) through four different multi-agent orchestration architectures across five LLMs. Real domain, real scale, real cost constraints.
Stanford (Tran and Kiela, April 2026) took a more controlled, theoretical approach. They asked a pointed question: if you give a single agent and a multi-agent system exactly the same compute budget (measured in thinking tokens), which performs better on multi-hop reasoning tasks? They tested across five architectures and four models, and they brought in information theory to explain what they found.
Google Research / Google DeepMind (Kim et al., April 2026) ran the broadest study. 260 controlled configurations, six different agent benchmarks, five architectures, three LLM families. Their goal was to build a predictive science of scaling: given a task and a model, can you predict whether adding agents will help or hurt?
Three different institutions. Three different methodologies. All published within six weeks of each other.
What They All Agree On
1. “More agents” is not a strategy
This is the headline finding across all three papers. Adding agents to a system does not reliably improve performance. In some cases it actively hurts it.
The Google team found a performance range of +80.8% to -70.0% depending on which architecture was matched to which task. That’s not a minor variance. A -70.0% drop means you built something that performs substantially worse than a single agent doing the same job. The Stanford paper found that under equal compute conditions, single agents matched or outperformed every multi-agent architecture they tested on multi-hop reasoning. The NYU paper found that their most sophisticated architecture (reflexive, with agents checking and correcting each other) was also the most expensive and the worst performer at scale.
The common thread: the performance gap between architectures isn’t random. It’s predictable. And the predictor is not “how many agents did you use.”
2. The real predictor is architecture-task alignment
All three papers converge on this. The question isn’t whether to use multiple agents. The question is whether the architecture matches what the task actually requires.
The Google team built a regression model to predict this alignment. It explained 37% of variance in performance outcomes and correctly predicted the best architecture for 87% of held-out configurations. That’s genuinely useful predictive power. Their model surfaces three moderating factors: how tool-heavy the task is (more tools amplify coordination costs), whether a single agent can already handle the task competently (above a 45% baseline accuracy threshold, adding agents tends to hurt), and how errors propagate through the chosen architecture (independent agents amplify errors 17x; centralized architectures contain them to 4x).
The NYU team found the same pattern applied in their domain. Reflexive orchestration (agents autonomously reviewing and correcting their own outputs) produced the best raw accuracy (F1 = 0.943) but at 2.3 times the cost of sequential processing. The hierarchical architecture landed at F1 = 0.929 at 60.7% of reflexive cost. When they optimized the hierarchical setup further (semantic caching, model routing, adaptive retry), they recovered 89% of reflexive accuracy at only 1.15 times sequential cost. The “best” architecture wasn’t the one with the most agents or the most autonomy. It was the one that matched the structure of the task.
The Stanford paper reached the same conclusion from a theoretical angle. They used the Data Processing Inequality from information theory to prove that when context is clean and compute is equal, a single agent is mathematically guaranteed to perform at least as well as any multi-agent system passing information through a chain. Every handoff between agents is a potential information bottleneck. The only circumstance where multi-agent systems cleanly outperformed in their experiments was when context was corrupted (degraded or partially substituted inputs). In that specific scenario, having multiple agents cross-reference and compensate for gaps becomes genuinely valuable.
So the alignment principle is consistent across all three papers: use the architecture that fits the information flow and error profile of the task, not the one that sounds most impressive.
3. Most reported multi-agent gains are compute artifacts
This is the most pointed finding in the Stanford paper, and it has implications for how a lot of published research should be read.
When researchers compare single agents to multi-agent systems, they typically don’t control for compute. A multi-agent system running five agents in parallel is spending five times the compute. If you measure accuracy without accounting for that, you’ll almost always find multi-agent systems “winning.” Tran and Kiela controlled for this by normalizing thinking token budgets across all configurations. Under equal compute conditions, the gains largely disappeared.
Their conclusion: most reported multi-agent performance advantages are not architectural advantages but they are compute advantages dressed up as design insights.
This is worth sitting with. A meaningful portion of the AI industry literature on multi-agent systems is measuring the wrong thing. If your benchmark doesn’t control for compute, you’re not comparing architectures. You’re comparing budgets.
The NYU and Google papers don’t make the same direct claim, but their cost-accuracy data tells a compatible story. The NYU team’s best-performing architecture (reflexive) was also the most expensive. The Google team’s overhead measurements for multi-agent systems ranged from 1.6 to 6.2 times the cost of single-agent baselines. The performance gains, where they existed, often didn’t justify that multiplier.
4. Every architecture has a specific failure mode
All three papers identified distinct failure patterns per architecture. This is more than a footnote. It matters for anyone trying to build reliable systems in production.
The NYU team mapped failure modes to specific task types in financial document processing:
- Sequential architectures failed on cross-table references (28.4% failure rate). They process linearly and can’t look back across document sections effectively.
- Reflexive architectures failed on ambiguous disclosure resolution (39.3%). The self-correction loop becomes a liability when there is genuine ambiguity. The agents “overthink” and converge on wrong answers with high confidence.
- Hierarchical architectures failed on agent coordination itself (12.4%). The overhead of coordinating specialist agents sometimes broke the chain.
The Google team found that independent multi-agent systems amplified errors catastrophically (17.2x) because there’s no coordination to catch or contain mistakes. Centralized architectures contained error amplification much better (4.4x), because a central agent can intercept and correct before downstream agents propagate mistakes.
The Stanford paper found that when context is degraded, multi-agent systems become more robust precisely because having independent agents cross-reference helps identify and compensate for corrupted inputs. The failure mode of single agents under context degradation is exactly the strength of certain multi-agent architectures.
These failure modes aren’t arbitrary. Each architecture has a structural reason for failing where it does. Understanding that structure lets you choose the right tool instead of discovering the wrong choice at production scale.
Where the Papers Diverge (or at Least Emphasize Different Things)
It would be too clean to say the three papers are just saying the same thing three ways. There are genuine differences in emphasis.
The Stanford paper is the most skeptical of multi-agent systems as a class. Their theoretical framework (the Data Processing Inequality) makes a strong claim: in the ideal case (clean context, equal compute), single agents can’t be beaten by design. The multi-agent advantage is situational, not structural. This is the most foundational result of the three papers, and it reframes what the other two are measuring.
The Google paper is more optimistic about multi-agent systems, but it’s a conditional optimism. They found genuine cases where multi-agent architectures significantly outperformed single agents, particularly on complex tasks where a single agent hit a capability ceiling. Their Finance-Agent benchmark showed an +80.8% improvement with centralized multi-agent orchestration. The point isn’t that multi-agent systems are bad. It’s that without understanding why they work (task decomposability, error containment architecture, compute accounting), you’re flying blind.
The NYU paper is the most practically grounded. Their Hierarchical-Optimized configuration is a concrete example of what “architecture-task alignment” looks like in production: a hierarchical structure with semantic caching, adaptive model routing based on query complexity, and a retry policy tuned to the domain. That specific combination recovered nearly all the accuracy of the most expensive architecture at a fraction of the cost. It’s a useful existence proof that the theoretical insights from the other two papers can be operationalized.
The three papers also disagree, implicitly, on what the right baseline for comparison is. Stanford normalizes by thinking tokens. NYU normalizes by per-document processing cost. Google normalizes by benchmark score against a single-agent baseline. These aren’t incompatible frameworks, but they’re measuring different things, and researchers should be explicit about which lens they’re using.
What This Means in Practice
If you’re evaluating or deploying AI agent systems, the collective message from these three papers is fairly direct:
Before adding more agents, ask whether a single capable agent can already handle the task well. The Google team’s 45% threshold is a practical heuristic: if your single-agent baseline exceeds 45% accuracy on the task, adding agents is more likely to hurt than help. You’re past the capability ceiling where architectural complexity pays off.
Match the architecture to the information structure of the task. Sequential tasks with clear handoffs benefit from sequential or hierarchical architectures. Tasks that require cross-referencing, error checking, or handling of ambiguous or degraded input benefit from reflexive or centralized architectures. Independent agent systems are appropriate only when subtasks are genuinely independent and error amplification risk is low.
Count all the compute. When comparing multi-agent to single-agent systems, normalize for total tokens consumed. An approach that uses 5x the compute and achieves 5% more accuracy may not be worth deploying. The Stanford finding that most reported MAS gains disappear under equal compute should be a standing challenge to any benchmark that doesn’t control for this.
Know what failure mode you’re accepting. Every architecture fails somewhere. Sequential systems fail on cross-references. Reflexive systems fail on ambiguity. Independent systems amplify errors. Centralized systems add coordination overhead. None of these failure modes is necessarily disqualifying, but you should know which one you’re accepting before you build around it.
The Bigger Picture
There’s something interesting about three groups publishing these papers within six weeks of each other. They weren’t coordinating. They were just asking the same question at the same time, because the question has become unavoidable: the industry is deploying multi-agent systems at scale, and we don’t yet have a coherent science of when and why they work.
These three papers are a meaningful step toward that science. The Stanford paper provides the theoretical foundation: information theory tells us why single agents can hold their own against multi-agent systems when compute is controlled. The Google paper provides the empirical framework: a predictive model that explains 37% of outcome variance and correctly identifies the right architecture in 87% of cases. The NYU paper provides the production reality check: what architecture-task alignment looks like when you’re processing 10,000 SEC filings and need to justify the infrastructure cost.
The convergence isn’t just intellectually satisfying. It’s practically useful. The multi-agent question isn’t “yes or no.” It’s “under what conditions, with what architecture, at what cost.” These papers give you the tools to answer that more precisely.
And for what it’s worth: the finding that the right single agent, given enough compute and clean context, can match a well-coordinated team of agents says something interesting about where the real work is. It’s less about coordination architecture and more about model capability, context quality, and clear task definition. Which sounds a lot like good engineering, regardless of whether humans or AI are doing it.
Sources: