
Until now, training a 100B+ parameter model required a cluster, a multi-million dollar budget, and a very patient CFO. A new paper just changed the equation.
There is an unspoken assumption running through almost every conversation about the AI industry’s competitive dynamics. It goes like this: the frontier belongs to the few. Training a large model (a real one, with more than 100 billion parameters) requires thousands of GPUs, weeks of compute time, and a budget that most universities, startups, and independent research teams will never see. The big labs built moats not just from their data or their talent, but from the sheer scale of infrastructure required to get in the game at all.
A paper published on arXiv on April 6, 2026 by Yuan, Zhengqing et al. proposes a different arrangement. Their system, called MegaTrain, claims to train models exceeding 100 billion parameters on a single GPU (not a cluster, not a rack, a single workstation-class GPU) and it does so without sacrificing full precision. If the results hold up under independent validation, it is one of the more consequential papers to come out of the AI systems space this year.
Let me walk through what they actually built, what the numbers mean, and what still needs to be true for this to change anything.
The Problem MegaTrain Is Solving
To understand why this matters, it helps to understand why training large models has always required so many GPUs in the first place.
The bottleneck is not processing power. It is memory. A 100 billion parameter model, running in full precision, needs somewhere in the region of 400 to 600 gigabytes just to hold the weights, gradients, and optimizer states simultaneously during training. NVIDIA’s current flagship H100 GPU has 80 gigabytes of high-bandwidth memory. The H200 pushes that to 141 gigabytes. Even the best hardware on the market cannot hold a large model in GPU memory in the conventional way. The standard solution is to split the model across dozens of GPUs, with all the distributed training complexity that entails: synchronization overhead, communication latency between nodes, and coordination infrastructure that itself requires engineering resources to build and maintain.
The capital cost follows directly. Cloud GPU pricing runs roughly $2 to $4 per GPU hour for H100-class hardware. Run 256 of them for several weeks and you understand where those multi-million dollar training cost figures come from.
MegaTrain’s core insight is to rethink where the model actually lives during training.
What They Built
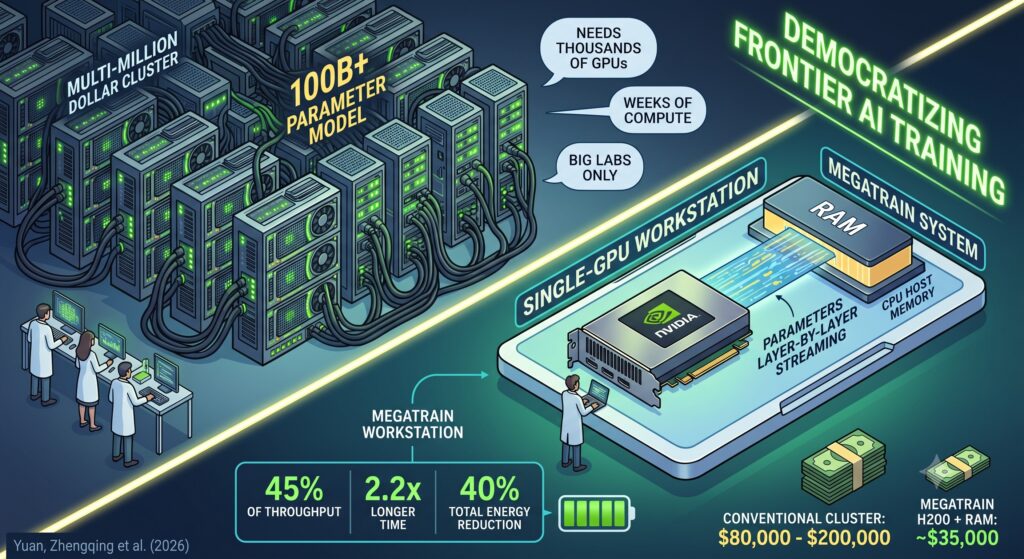
The architecture is conceptually elegant. Instead of treating GPU memory as the primary store for model parameters, MegaTrain moves everything to CPU host memory — the ordinary RAM that a workstation has in abundance — and treats the GPU as a transient compute engine.
During the forward pass, parameters are streamed layer by layer into GPU buffers on demand and released immediately after computation. During the backward pass, the same parameters are uploaded again, gradients are computed on the GPU, and then streamed back to host memory. The intermediate activations are kept in GPU buffers with a block-wise recomputation strategy that prevents them from accumulating. The result is that GPU memory consumption stays nearly flat regardless of model size.
In practice, the Microsoft Azure engineering team that analyzed the paper found that peak GPU memory utilization remained between 35 and 40 gigabytes whether the model being trained had 30 billion parameters or 175 billion. That is a remarkable property. A conventional approach would require proportionally more GPU memory as model depth increases. MegaTrain’s memory profile is essentially constant.
The reported headline experiment: a 175-billion parameter model trained on a single NVIDIA A100 with 80 gigabytes of GPU memory. Conventionally, that same hardware would support only 15 to 20 billion parameters. A companion run trained a 120-billion parameter model on a single H200 with 1.5 terabytes of host RAM.
The Trade-offs Are Real
MegaTrain is not free lunch, and the paper is reasonably transparent about the costs.
The throughput hit is significant. Because parameters are constantly being streamed in and out of GPU memory rather than sitting resident, MegaTrain runs at approximately 45% of the speed of conventional in-memory training. In wall-clock terms, that translates to roughly 2.2 times longer to complete equivalent training steps. If a conventional 8-GPU cluster would finish a training run in a week, a single-GPU MegaTrain setup would take about two and a half weeks.
For many use cases, this is an acceptable trade. Trading time for capital is a calculation that resource-constrained teams make all the time. A startup that cannot afford a cluster but can run a workstation for two and a half weeks instead of one week is in a fundamentally different position than a startup that simply cannot run the experiment at all.
The energy story is more interesting. The Microsoft analysis found that single-GPU MegaTrain consumes 85% less power than equivalent 8-GPU distributed training for the same model, resulting in a net 40% reduction in total energy consumed, even accounting for the longer training duration. That is not a trivial number for organizations thinking about either operating costs or sustainability commitments.
The hardware requirement worth flagging is the RAM. For models at the 70 to 100 billion parameter scale, MegaTrain requires roughly 1 terabyte or more of host memory. This is not standard workstation territory — 1.5 terabytes of DDR5 costs somewhere between $3,000 and $5,000 today, which is far cheaper than equivalent GPU memory capacity but still means you are not running this on an off-the-shelf machine. The ideal platform, per the authors, is something like the NVIDIA GH200 SuperChip, which provides 900 gigabytes per second of bandwidth between GPU and CPU memory via NVLink.
What the Numbers Mean in Context
The cost comparison is where the implications become concrete.
A single-GPU MegaTrain setup built around an H200 and the necessary RAM comes to roughly $35,000. A multi-GPU cluster capable of the same training task conventionally costs $80,000 to $200,000 in hardware alone. The savings range from $45,000 to $165,000 per setup.
Put that against where the industry has been. Training GPT-4 reportedly cost north of $79 million in compute. Gemini Ultra reached $191 million. DeepSeek V3’s $5.6 million training run was treated as a shock to the system when it was disclosed. MegaTrain is not suggesting you can train frontier models for pocket change — the larger the model and the longer the run, the more hardware time accumulates — but it is suggesting that the capability to train 100 billion parameter models is no longer gated behind infrastructure budgets that only a handful of organizations can reach.
For university research groups, independent labs, and startups doing foundational work, the difference between a $200,000 cluster and a $35,000 workstation is not a matter of degree. It is a matter of whether the project happens at all.
What Still Needs to Be True
The paper’s results have not yet received independent third-party validation across diverse hardware configurations. The authors’ throughput and efficiency numbers come from their own experiments, and the broader AI community has not yet had time to reproduce them at scale.
This matters because memory-centric training approaches have been attempted before. Microsoft’s DeepSpeed pioneered ZeRO optimization for distributing optimizer states across devices. Projects like FlexGen explored aggressive offloading to enable inference of large models on limited hardware. What MegaTrain claims to add is full-precision training (not inference, not quantized weights, but proper training) on a single GPU, without the model quality degradation that typically comes with aggressive memory compression techniques. That is a more specific and more demanding claim, and it deserves scrutiny.
The fact that the codebase is open-source (available on GitHub at DLYuanGod/MegaTrain) means independent engineers can begin reproducing and stress-testing the results. That process will take months, and the community’s verdict will matter more than the paper’s reported numbers.
Why This Matters Beyond the Hardware
There is a broader story here that goes past the technical details.
The AI industry’s current competitive structure is partly a function of infrastructure scarcity. The labs with the most GPUs can run the most experiments, iterate the fastest, and train the largest models. Everything downstream (talent recruitment, research agenda-setting, commercial leverage) flows partly from that hardware advantage. It is not the only thing that matters, but it is a real structural factor.
MegaTrain, if it validates, is one of several recent signals that this structure is under pressure. DeepSeek’s $5.6 million V3 training run was another. The efficiency race (Mixture of Experts architectures, sparse attention mechanisms, improved training algorithms) is consistently pushing down the cost floor for capable models. The trend is not linear, and frontier training costs are actually increasing in absolute terms as labs push to larger scales. But the cost of reaching a given capability level is falling, and the minimum viable infrastructure to do serious model work is shrinking.
That matters for who gets to participate in shaping what these systems become. Research institutions that cannot afford hyperscale GPU clusters can still run serious training experiments. Teams working on domain-specific models for medicine, law, materials science, or other specialized fields can build and fine-tune at a scale that was recently inaccessible. The barrier between “consumer of AI” and “producer of AI” just got lower.
Whether MegaTrain itself becomes a production standard or gets superseded by the next iteration of this idea is less important than what it represents: the engineering community is systematically attacking the assumption that large model training requires large infrastructure. The assumption is losing.
Sources:
ByteIota. “MegaTrain: Train 100B LLMs on Single GPU ($35K vs $200K).”
GPUnex Blog. “How Much Does It Cost to Train an AI Model in 2026?”