
A Shanghai lab just shipped a model that does at 1M tokens what full attention can’t do at any price. The architecture story is more interesting than the benchmark numbers.
There is a particular kind of AI announcement that gets buried under the noise of benchmark numbers and marketing claims, where the genuinely interesting thing is not the score but the engineering decision behind it. MiniMax M3, released on June 1, 2026, is one of those.
The headline numbers are real: the model scores 59% on SWE-Bench Pro, which puts it ahead of GPT-5.5 and Gemini 3.1 Pro on software engineering benchmarks. It supports a one-million-token context window. It processes text, images, and video natively. It runs at roughly 100 tokens per second output, about three times faster than Claude Opus. For a model accessible via API at promotional pricing of $0.30 per million input tokens and $1.20 per million output tokens, that combination is genuinely striking.
But the benchmark story is not the reason to pay attention to M3. The reason to pay attention is the architecture decision underneath all of it, and why MiniMax made the same bet twice, having abandoned it once already.
The Problem That Standard Attention Cannot Solve
To understand what MiniMax built, it helps to understand what they were up against.
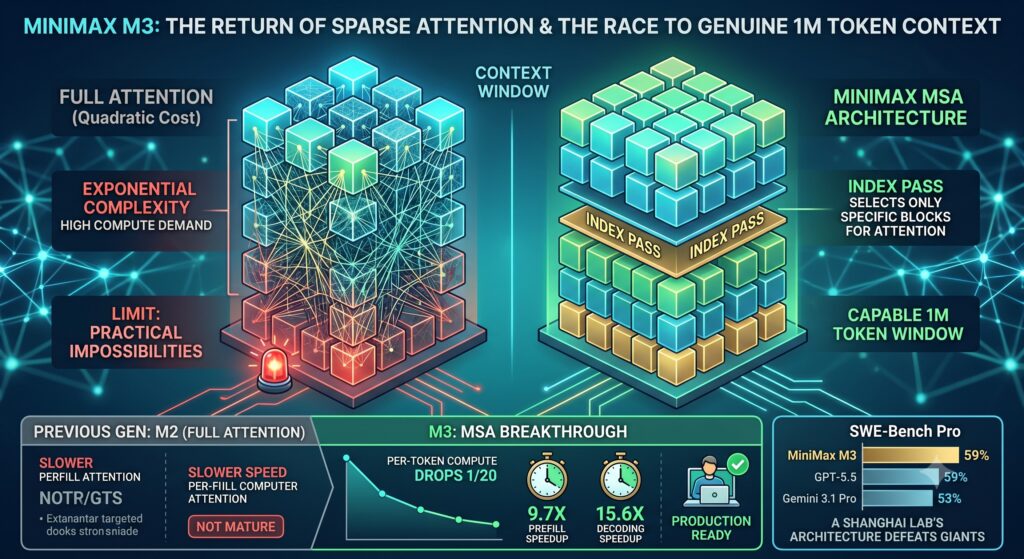
The transformer architecture that underpins essentially every major language model today uses a mechanism called attention to decide which parts of the input are relevant to each other. In its standard form, this attention mechanism is quadratic. That means as context length grows, compute cost grows as the square of the sequence length. Double the context, quadruple the compute. Extend to a million tokens under standard full attention and the compute requirements become practically impossible to serve at reasonable cost.
This is why long-context models have historically been slow, expensive, or both. It is also why model providers have been cautious about advertising very long context windows as production features rather than marketing specifications. The gap between “our model supports 1 million tokens” and “our model can process 1 million tokens quickly enough to be useful in production” has been wide and mostly undiscussed.
The research community has spent years trying to design attention mechanisms that break the quadratic relationship. Sparse attention, where the model pays attention to only a relevant subset of context rather than everything simultaneously, is one of the most promising approaches. The idea is to have a small selection mechanism decide which blocks of context actually matter, then run full attention only over those blocks. Done well, the compute cost scales far more gracefully with context length.
Done well is the hard part.
The Architecture MiniMax Built, Abandoned, and Built Again
This is where the story becomes genuinely interesting.
Sparse attention is not a new idea. MiniMax had explored it before M3. In the technical report for their previous M2 architecture, the team wrote that “the infrastructure for linear and sparse attention is much less mature” than full attention, and that “efficient attention still has some way to go before it can definitively beat full attention.” They chose full attention for M2. Sparse attention was shelved.
That was approximately one year ago.
With M3, the same engineering team came back to sparse attention and shipped it at production scale with order-of-magnitude performance improvements. They call the new architecture MiniMax Sparse Attention, or MSA. The fact that they reversed course is a meaningful signal: not evidence of inconsistency, but evidence that the underlying infrastructure actually caught up with the theory. The bet they were not willing to make a year ago is a bet they are now putting in front of every developer who uses the API.
The way MSA works is worth understanding at a conceptual level. Standard attention computes relationships across every token in the context simultaneously. MSA partitions the key-value cache into blocks and selects only the relevant blocks for each query. The selection is handled by a lightweight index pass; the main attention layer then processes only the chosen blocks. Memory access is contiguous rather than scattered, which matters significantly for hardware efficiency. The authors describe this as a “KV outer gather Q” approach, and report that it runs more than four times faster than existing sparse attention implementations under M3’s configuration.
The practical result at a one-million-token context: per-token compute drops to one-twentieth of the previous generation, prefilling runs approximately 9.7 times faster, and decoding runs approximately 15.6 times faster. At full context length, the model is not just less expensive to run. It is qualitatively more usable. The difference between a model that takes several minutes to process a million tokens and one that does it in seconds is the difference between a research curiosity and a production tool.
What One Million Tokens Actually Enables
It is worth pausing on what a genuinely usable million-token context window makes possible, because the use cases are not always obvious from the specification sheet.
Software engineering is the clearest case. Modern codebases are large. A serious commercial application might have hundreds of thousands of lines spread across dozens of files, with implicit dependencies, naming conventions, and architectural patterns that span the entire codebase. A model that can hold all of that context simultaneously does not just answer questions about individual functions. It can reason about how a change in one module propagates through the system, where the architectural inconsistencies are, what a refactor would touch. MiniMax’s SWE-Bench Pro score of 59% is partly a product of the architecture enabling this kind of whole-codebase reasoning rather than windowed approximations of it.
Legal and financial document analysis is another obvious domain. A complex contract, a full regulatory filing, a year of correspondence in a litigation: these routinely exceed what 128K or even 200K context windows can hold. The practical workflow today involves chunking documents, summarizing chunks, summarizing summaries, and hoping nothing important fell through the seams. A model that can hold the entire document in context simultaneously removes that approximation.
Research and synthesis tasks follow the same pattern. Reading and cross-referencing twenty long academic papers, maintaining a coherent synthesis across all of them simultaneously, catching contradictions across sources: this is the kind of work where context length is a genuine capability multiplier rather than a theoretical specification.
The agentic use case may be the most significant in the long run. Agents operating on long-horizon tasks, like debugging a large system over many steps, managing a complex project across many interactions, or operating a computer through an extended workflow, accumulate context fast. A million-token window means fewer mid-task failures caused by the model losing track of what happened earlier in the session.
What the Benchmark Numbers Cannot Tell You
MiniMax reported all benchmark results themselves. At the time of this writing, open weights had not yet been released (promised within ten days of the June 1 launch), which means independent engineers could not yet reproduce the architecture claims.
This matters in two ways. First, self-reported benchmarks are not the same as community-validated benchmarks. The SWE-Bench Pro numbers are notable, but they become significantly more meaningful once independent researchers reproduce them on open weights. Second, the efficiency numbers — the 9.7x prefill speedup, the 15.6x decoding speedup — are hardware-profiling results from MiniMax’s own infrastructure. Different hardware configurations, different prompt distributions, and different use cases may produce different figures.
The VentureBeat coverage at launch was careful to note this, and it is worth carrying that caution through any analysis of M3’s specifications until the weights are public and the community has had time to evaluate them.
There is also a geopolitical dimension worth noting plainly. MiniMax is a Shanghai-based company, publicly listed on the Hong Kong Stock Exchange since January 2026, preparing a secondary listing on Shanghai’s Star Market. China’s 2017 National Intelligence Law requires domestic organizations to cooperate with government intelligence requirements when asked. This does not tell you anything definitive about M3’s data practices, but it is relevant context for organizations evaluating whether to build production systems on top of it, particularly those handling sensitive data.
What It Means for the Broader Attention Architecture Race
The most important thing about M3 is not whether its benchmark scores hold up on independent validation. It is what the release signals about the state of the efficiency race at the architecture level.
Anthropic, Google, and OpenAI all have sparse and efficient attention research programs underway. None of them have shipped a flagship model with comparable public efficiency commitments at one-million-token context. A company operating out of Shanghai just publicly demonstrated that production-ready sparse attention at this scale is achievable, and did it by reversing their own previous decision after concluding that the infrastructure had matured enough to make the bet.
That is a meaningful data point for the broader research community. The practical barrier to deploying sparse attention at production scale has been “the infrastructure isn’t there yet” for several years. MiniMax is now arguing, with working code, that it is. If that argument holds up, it accelerates the timeline for other labs to follow.
It also continues a pattern that has been visible since DeepSeek’s training cost disclosures in late 2024: the frontier is being driven from multiple directions simultaneously, and the assumption that efficiency innovation would follow capability innovation with a significant lag is not holding. Teams are finding ways to make large models faster, cheaper, and more capable in ways that compound. Each breakthrough in one dimension creates new room to push in another.
The Story Behind the Return
There is something worth sitting with in the decision MiniMax made here. They looked at their own previous engineering judgment, that sparse attention was not mature enough, evaluated it against a year of infrastructure progress, and reversed course. Then they shipped.
That kind of principled willingness to revisit prior conclusions is not universal in engineering organizations, where previous decisions accumulate into constraints that are difficult to unwind. The fact that the infrastructure matured faster than the original team expected, and that they recognized and acted on it, is arguably as interesting as the technical result.
M3 is a bet that attention efficiency is now a solved engineering problem, at least at the scale MiniMax operates. The next twelve months will tell us whether the broader community agrees.
Sources:
MiniMax (official release). MiniMax M3 launch announcement. June 1, 2026.
DataNorth. “MiniMax launches M3: Specs, benchmarks, and analysis.”
FelloAI. “MiniMax M3 Specs, Benchmarks, and Pricing (2026).”
Lushbinary. “MiniMax M3 Developer Guide: Benchmarks & Pricing.”