
Why standard regression fails at binary classification and how Logistic Regression models the probability of reality.

This week, I dove into Module 13: Logistic Regression. Despite its name, this isn’t a tool for predicting continuous numbers like house prices; it is a core machine learning method for classification. It is essentially a “generalized linear model” designed to handle categorical outputs—specifically binary outcomes like yes/no, success/failure, or buy/don’t buy.
Here is what I learned about why this model is a staple in the data scientist’s toolkit:
1. The Problem with Being Too Linear
If you try to use standard linear regression for binary data (0s and 1s), you run into a logical wall. A straight line can predict values above 1 or below 0, which makes no sense when you are trying to predict the probability of a “yes”.
Logistic regression solves this by using the sigmoid function to create a curved “S-shape”. This function maps any input into a value strictly between 0 and 1, making it perfect for estimating probabilities. The formal logic follows:
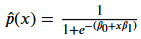
2. Shaping the Curve: Ꞵ0 and Ꞵ1
I learned that we can tune the “behavior” of our probability curve by adjusting its parameters:
- The Intercept (Ꞵ0): Shifts the entire curve left or right in space.
- The Slope (Ꞵ1): Controls the steepness. A high Ꞵ1 means the model is very “sure” and makes a sharp switch from 0 to 1, while a low Ꞵ1 creates a smoother, more uncertain transition.
3. The Threshold Game: Balancing Risks
While the model outputs a probability (e.g., 0.65), we often need a hard decision. We use a threshold (often 0.5) to decide the final class. However, I learned that 0.5 isn’t always the best choice:
- In Healthcare: You might lower the threshold to raise fewer false negatives (missing a sick patient), even if it raises more false alarms.
- In Finance: For credit card fraud, you might adjust the threshold to ensure you don’t miss a single fraudulent transaction, even if it means checking more legitimate ones.
4. Interpretability and Feature Significance
One of the biggest advantages of Logistic Regression is that it isn’t a “black box”. It allows for rigorous statistical testing:
- Z-scores and P-values: These help us determine if a specific predictor (like credit score or income) is actually statistically significant or just noise.
- Regularization (L1 & L2): These techniques prevent overfitting by penalizing large coefficients, ensuring the model generalizes well to new, unseen data.
Conclusion
Logistic regression is the perfect middle ground between simplicity and power. It handles feature interactions better than Naive Bayes and provides confidence levels that models like KNN cannot. Whether it is predicting customer churn or assessing the risk of a loan default, it remains one of the most reliable models in the industry.